
最近我看到一个新闻,我是震惊的。
《自然》杂志统计了各个机构的顶尖论文数量,发布了2024年的Nature Index,中国高校在全球前十名中占了九所,一片大红。
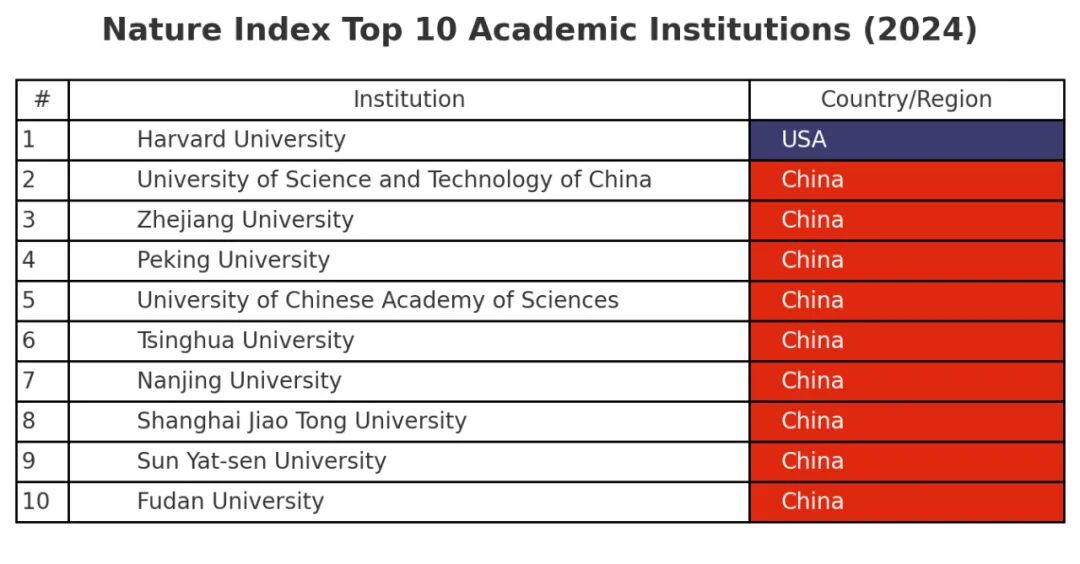
其实去年就已经8所了,今年我旦成功把MIT挤下前十。
二十年前,2005年我还在读书那会,哪见过这种阵势。
甚至十年前,2015年的排名,也可能更符合不少人对当前中国科技的印象吧。

有不少人持有这样的观点,中国造不出光刻机,也就造不出自己的芯片,英伟达一枝独秀。AI大模型又是都用英伟达芯片,所以 AI 竞赛上,中国是赶不上美国的。
实际情况是分层的。
芯片层面,美国绝对领先。英伟达一枝独秀。
大模型层面,美国略优,差距存在但不悬殊。OpenAI和Google 也领先,但是阿里Qwen、DeepSeek等模型也并不弱;甚至多模态模型上,可灵即梦海螺生数爱诗万相全方位领先国外(最近的veo3和香蕉才给美国扳回一城!)
ToC应用层面,中国领先了。
我画了一个竞争态势如下图,详细的模型和技术暂时不展开。
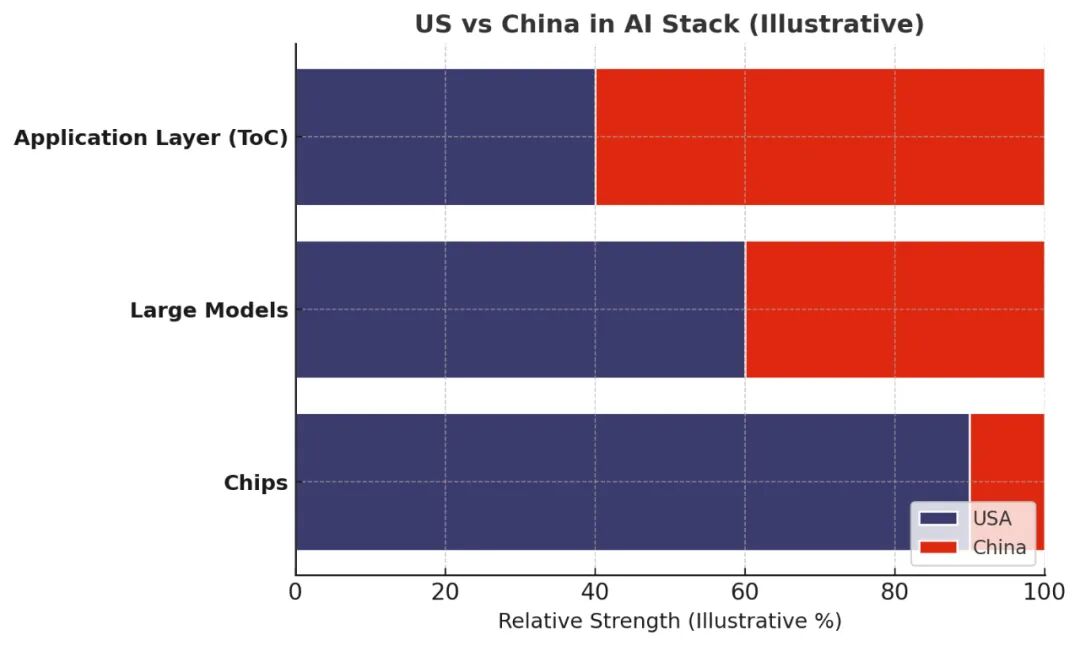
下层技术的优势并不能天然扩散到上层技术中,每上升一层,所需的技术就多出很多新的维度。大模型,比拼的是算法、算力和数据,这三样都要强,芯片技术只代表算力的强弱。算法人才中国并不犯怵,甚至美国 AI 大厂里的核心算法人员还是华人。而数据上,语言数据简中要差很多,但是多模态数据强啊。所以综合起来,大模型层的差距就被拉近了。
同样的逻辑,下层大模型的优势,并不能天然扩散到上层应用中。大模型只是解决了智商问题,应用还有产品化能力和生态/场景。而中国拥有的统一大市场和大量线上化的场景和数据,广泛的工程师红利,对AI行业中一些灰色的伦理、法律问题采取更包容的态度,这些都是催生AI应用的良好土壤。不少中国团队的 AI 应用还能走出海外。根据 aibase 的统计,在移动端AI应用产品Top 50里,中国团队占据了44%。
再说回来,就算只能用英伟达芯片又怎么样呢,不少重要的模型训练的突破是中国团队或者华人做出的。比如何恺明的ResNet、Edward Hu的LoRA、杨植麟的Transformer-XL、DeepSeek的多头潜在注意力架构、谢赛宁的DiT,更不得不提阿里的Qwen,可以说是开源被使用最广泛的基础模型之一,斯坦佛大学教授“AI教母”李飞飞都用Qwen来finetune她的推理模型。
近日传OpenAI研究员、思维树CoT的作者姚顺雨被腾讯用亿元薪酬挖角。这个消息被腾讯辟谣了,只是不知辟的是加入腾讯的谣,还是亿元薪酬的谣。
中国科技,也是慢慢好起来了。
希望行业和资金也会慢慢好起来。
发表回复