
(一)
近日,浑水披露的一份匿名的89页做空瑞幸咖啡的报告堪称质疑的典范。这份报告从结论来说,用89页论述了一个众所周知的废话:瑞幸是不能赚钱的。
但是这个废话是需要论证的。
特别是在瑞幸咖啡已经在美国证监会公布了2019年Q4业绩快报,其中提到瑞幸咖啡的单店已经开始盈利了。瑞幸公司管理层是拥有最多的内部信息,他公布了多个维度的内部信息和分析支持了“瑞信咖啡单店开始盈利”的结论,审计师E&Y没有反对,美国证监会也没有反对。瑞幸咖啡已经完成了他的举证义务。
现在轮到质疑的人完成他的举证义务了。
套用陈铭说的话,你要承担反对方的责任,不是简单的挑刺。反对是需要论证的。
如果只是一个吃瓜群众,只要知道上面这句话,再等等看瑞幸咖啡官方的回应就能继续吃瓜了。但是作为一个被疫情死死按在家里的人,我来拆解了这89页报告,再锻炼下我们论证分析的能力。
附:做空报告原文(百度网盘链接)
链接:https://pan.baidu.com/s/1lJ-EuP28wWviZWD7WN7GTw
提取码:n16q
(二)
在拆解报告之前,我先普及一下瑞幸咖啡烧这么多钱,为什么还能在NASDAQ上市。对瑞幸熟悉的可以直接跳过这一部分。
瑞幸的商业模式可以放在这个框架下来拆解:利润 = (销售单价-成本) * 单店销售量 * 店面数量规模。那么之前烧钱随后如何挣钱?其中成本端简化成一个都放在了括号里了,其实严谨来说应该分为单杯变动成本、店面固定成本、公司固定成本。
- 原来销售价格 – 成本是负的,亏钱卖咖啡。瑞幸说,是因为折扣做得多。折扣属于促销市场活动,烧钱主要是为了建设品牌和培养用户习惯。正常价格销售,毛利是正的。
- 每个门店开店是有固定的房租人工成本的。为了覆盖这些固定成本,每一杯咖啡都挣钱还不行,每天还要卖足够多的量。
- 一直开店,开店,开店。把单店利润反复复制。
不管原来烧过多少钱,只要从近期的某个时候开始,扭亏为盈,越来越盈,那就是好公司。
这个近期,就是2019年Q4。瑞幸在上市公司Q4业绩公告中说,单店已经扭亏了。
具体而言,平均销售价格从上市时候的9元上涨到15元,平均每店每天销售的咖啡杯数从上市时的293杯上涨到493杯。同时,瑞幸的门店也开了4500家。诺你看我的财务报表,主营业务亏损缩减了,这是审计过的哦。按这个增长趋势,瑞幸会挣很多很多钱。各位投资人爸爸,买我吧!
瑞幸一直说自己在烧钱,门店数量快速上升,DAU增加,跟我们的个人感觉是相符的。直至上市的时候也是这副样子。
走在上海的街上,确实看到越来越多瑞幸蓝色的门店,确实有很多朋友同事下载了瑞幸咖啡的APP,也经常收到各种各样的折扣券,这么低的价格真的好划算。亏钱补贴消费者,真是薅资本主义羊毛的良心企业。
质疑瑞幸的文章很多,瑞幸还要亏多久,有没有盈利的一天。
瑞幸就这个态度:你说我过去在亏,我认。但是你说我未来永远会亏,未来都还没来,没人说服的了对方。
然后,在2019年Q4,瑞幸说它单店层面盈利了。
他说,我现在也不亏了。
这就打了很多人的脸。瑞幸这个模式,单店怎么可能盈利呢。
(三)
让我们用这样的顺序来学习。列出一句命题,先自己想想,该怎么论证它是真的。然后看看浑水怎么做的。
命题1:瑞幸说全国平均每店每天销售的咖啡493杯,数字偏大了。
错误论证1:做做Market Sizing。对标下星巴克每天能做多少杯,或者对标下其他咖啡品牌的经验。同时用每天营业时间倒推,得到每1分半能卖一杯咖啡。从理论产能极限来看,几乎已经是100%满负荷不停。
错误论证2:我们说瑞幸现在一直在烧钱,唯一的稻草就是NASDAQ的增发。要增发必须给投资者一份过得去的答卷,所以管理层绝对有充分的理由和能力调高这个咖啡销量。他可以简单改下APP数据库里的记录,也可以通过供应商占款再回流的形式做成销售收入……
不完善论证1:我身边就有几个瑞幸咖啡的门店,我去那里看看,每小时平均出多少个订单,然后折算一下。
不完善论证2:我去想办法看看某家门店的收银机统计下,看不了收银系统,看看一天打出的最后一张水单表编号也行,总之都有办法。
以上所有的论证,都有一个共同的缺点:这都只是疑点,不是证据。
- 星巴克每天只能做300杯那能说明什么,为什么瑞幸不能比星巴克每天多50%?
- 满负荷100%不停能说明什么,瑞幸门店就是满负荷运营啊,这是他们的竞争优势。
- 身边这个瑞幸门店或收银机统计一天只能做300杯那能说明什么,你可能去的是偏僻的门店。
- 管理层有理由和能力调高销量,不等于管理层实际真的已经调高了销量。
所以这些论证方法都不能成立。
让我们来看匿名报告怎么做的。
他首先从瑞幸APP上,一个城市一个城市,把瑞幸的门店名称、位置都抓了出来,做成了一张 Master Data File。
基于这张Master Data File,进行数据汇总,得到如下的汇总结果:截至2019年12月31日,从瑞幸APP上数到4409个门店,分布在53个城市,分成办公楼门店、商场店和其他店的类型。和瑞幸咖啡发的年报上的数据核对:4507家门店,只差了2%。基本上可以保证这个清单的完整性了。
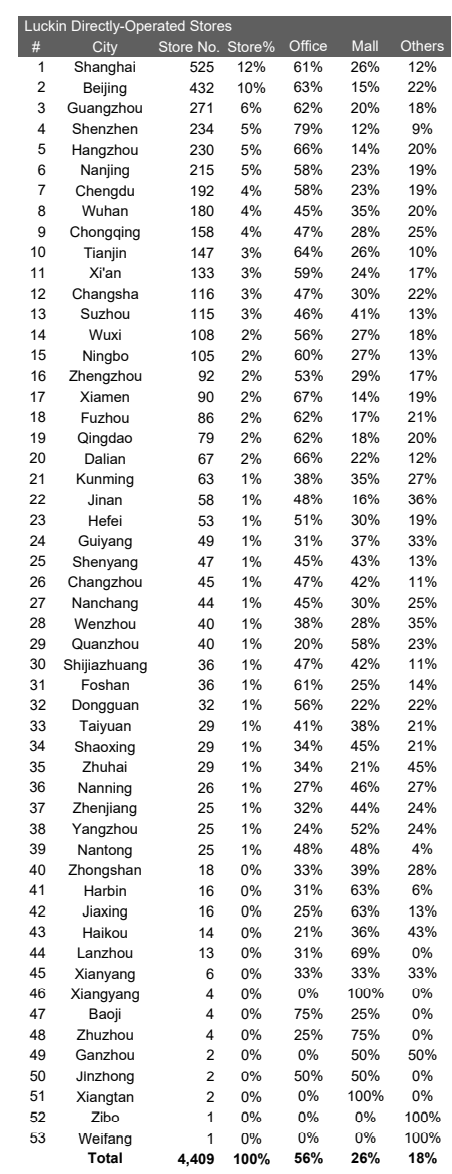
接下来骚操作来了,他对这4409家店按照类型和城市进行了分层抽样,然后派人暗访了981家门店(占总样本的22%),数出每个门店的每天卖了多少杯咖啡——数出来,平均每店每天263杯,比管理层说的495杯少了将近一半。
用统计学和分层抽样,而且抽样率大大超过拥有统计显著性的抽样数。如过按审计方法,基本抽40-100个样本就可以进行统计分析了——解决样本代表性问题。
接着,如何统计订单呢。线下订单看POS机操作多少次,线上订单看纸袋数量——这个统计方式只多不少,解决“外人无法准确判断订单数”的问题。
现场的人数数,同时全程录像,回头第二个人对着视频再数一遍——双人独立复核解决“万一人工数错了呢”的问题。
再强调一遍,反对是要论证的。
同样,反对的反对也是要论证的。
假设其他人要反对这个抽样的样本代表性还是有问题,那么需要明确论证,以上抽取的981家门店,或者抽取的具体天数存在bias,需要同样或者更高强度的统计显著性。
(四)
命题2:瑞幸咖啡停止烧钱的补贴之后,就能挣钱了。
错误论证1:很容易想到,很多买瑞幸咖啡的顾客就是存在拉新补贴、折扣券和价格才购买瑞幸的。这些顾客都是价格敏感的顾客,价格上涨后销量肯定下降。
不完善论证1:我的某某朋友说,如果瑞幸咖啡取消这些补贴,肯定不会买瑞幸了。我莫某朋友也这样,我也这样,我认识的人都这样。
看看匿名报告怎么做——“顾客价格敏感的”这句话是要论证的。
瑞幸的年报里找到一个图表,瑞幸把客户按照注册的月份分为一个群组,并跟踪这个群租随后每个月份的留存情况。瑞幸咖啡用来说明,他的用户留存率随着用户注册时间先下降后稳定上涨,如下图,横轴表示用户注册的月份数。
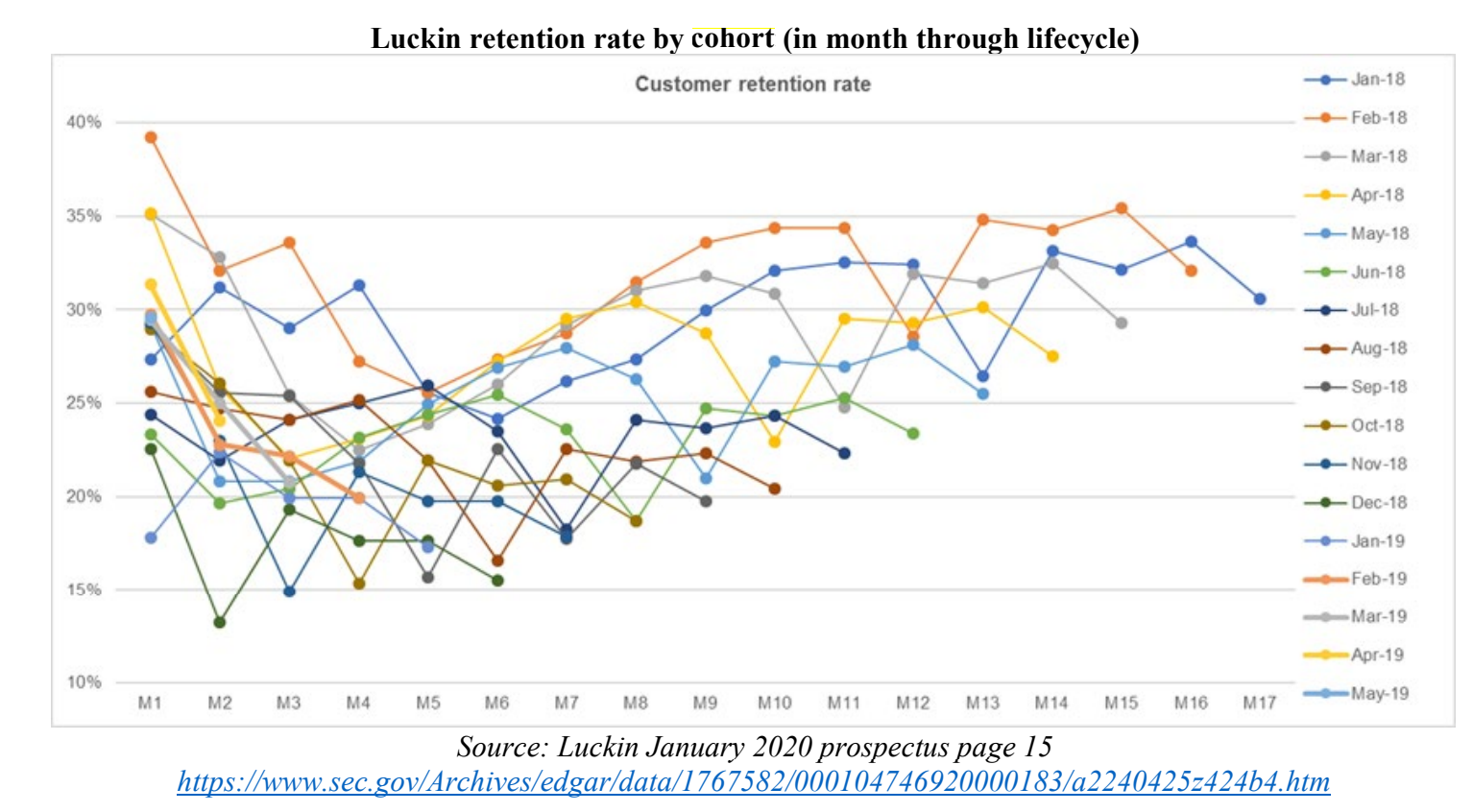
报告把这个图标的横坐标微调了一下,把用户注册月份数改成具体的日历月(比如2019年1月)这样。所以每个群组的线不变,只是简单左右平移到了对应的月份,变成了下图这样:
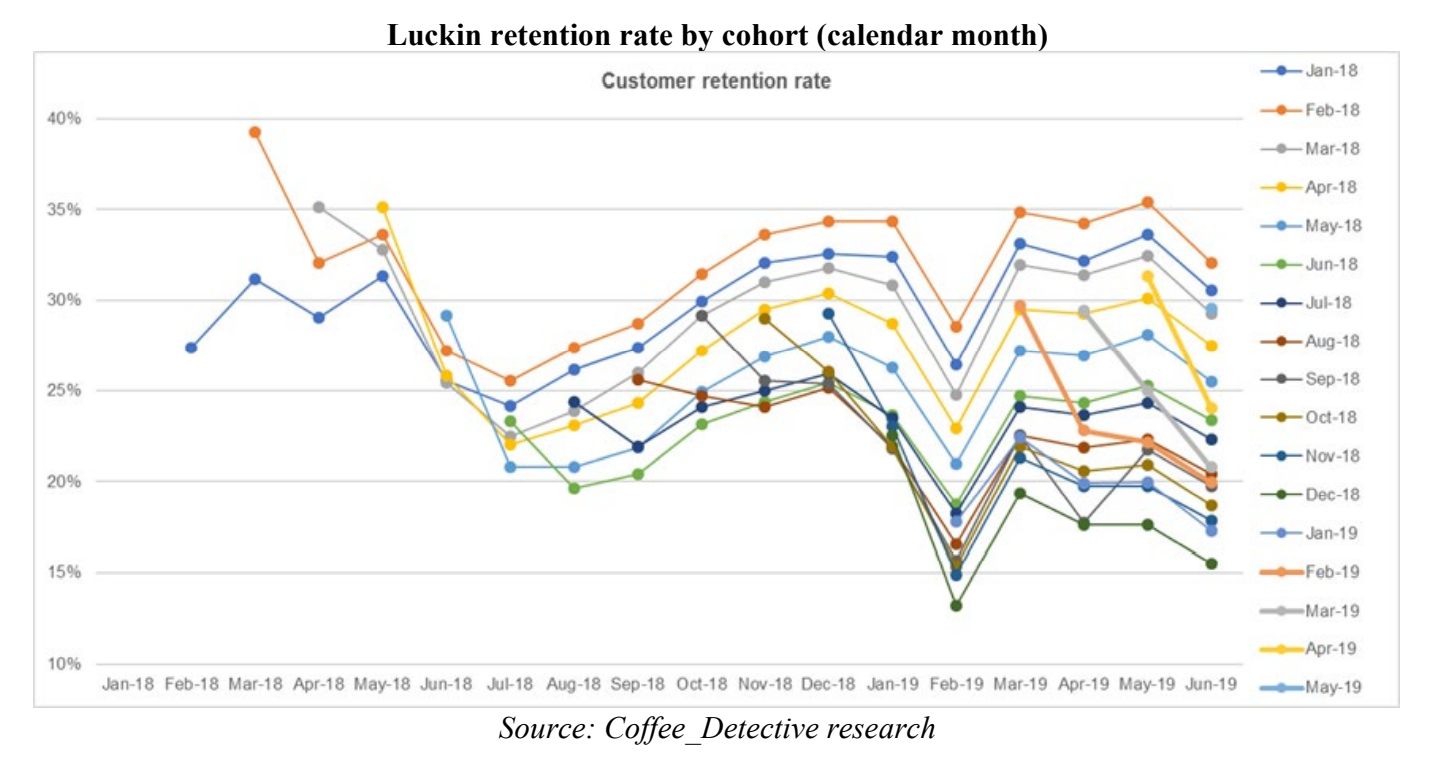
豁然开朗,有没有。上图究竟是什么杂七杂八的线条啊。
这告诉我们,用户的留存率其实跟用户注册的月份数没有任何关系,只跟日历月有关系。
把交易量的图也平移一下,得到相似的形状:
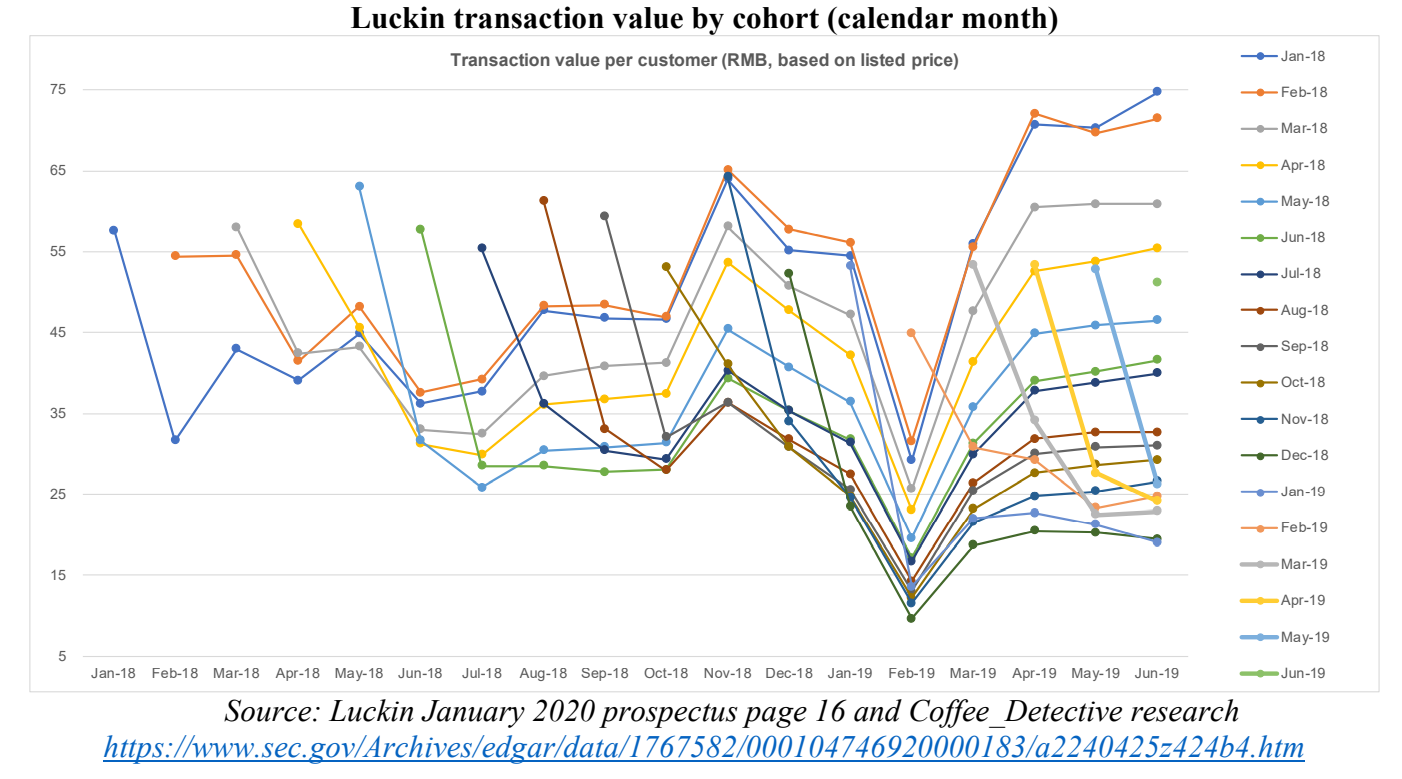
用户留存率、销售量在2019年2月同时都深深地掉下去了。让我们看2019年2月发生了什么:瑞幸在上市后的19年没有那么狠地推补贴了。但是当瑞幸发现,补贴一取消,销量就猛掉,在2019年3月11日,开启了每周“买7件商品,抽500万现金”的大手笔补贴促销。销量和用户留存率又回来了。
把价格和销量化成二维图标,这就是经济学的价格弹性曲线。没有了补贴,销量就大幅下跌,基本可以论证“顾客是价格敏感的”了。
这样也避免了“某某朋友觉得”这种个案代表性问题。
(五)
让我们看看无效的证据通常有什么样的表现形式。要时时刻刻小心这些陷阱。这些只能做Indicator,但不是Evidence。
1. 用可能性/高概率当成事实。
这事情有发生的可能性,甚至比较高的可能性,但不代表就会发生啊。这是经常会犯的错误。常见的是纯粹因为想不出第二种发生的可能性,而把可能性当成了100%,并推论成了事实。
即使既有足够能力也有充分动机,可能性到事实仍然需要一个惊险的跳跃,那就是实际发生。任何实际发生的事情都会留下各种痕迹,要证实必须找到这样的综合且无可辩驳的痕迹。
错误举例:”我家邻居阳台上晾了一块腊肉,我家猫可以跳过去,把这块肉扯碎扯到地上。我家猫以前也干过这个事情。这次不是你家猫干的还能是谁?”
错误举例:“2015年的Nature论文显示人类有能力在实验室制造病毒,武汉P4实验室又是中国病毒研究的前沿,而且我听说他们实验室管理很混乱,新冠病毒就是人为制造不小心泄露出来的。”
2. 诉之“不合常理”的低概率。
这事情概率太低,怎么可能恰好发生,说明这事情是假的。这属于产生怀疑的前置信号,但不叫证据。有了怀疑的信号,需要干的事情是寻找完整的证据和论证。信号不等于论证。
对任何事情,我可以举出无数不合理的信号。世界其实是充满了偶然。
错误举例:“你不打他,他怎么会打你呢?”
错误举例:“印度学者发现,新冠病毒2019-nCoV的基因序列发现4个独有插入的片段。这在所有其他冠状病毒中都不存在,这在自然界中不太可能是偶然的。新冠病毒是人类制造的。” / “人类这么精密的生命,在自然界通过进化变异是不可能的。人类一定是由某种高等智慧生物制造的。”
3. 以个案代表总体,却不建立个案的统计典型性
用我之前的经历,我朋友的事情,我看过有个代表性案例是怎样的,作为证据。
错误举例:“我有朋友整天不读书,最后做生意,现在有好几套房了,比绝大多数大学生都多吧。读书有啥用。早出来生意场打拼学做生意,比读书更能挣钱。”
错误举例:“报告说平均每家店每天才200多单,他一定是故意挑了流量低的店,或者在流动低的一天去统计的。淮海路百盛3楼的店,周末下午排队时间一刻钟左右,我打工的某工业区,元旦后开了一家,我们40个人的办公室每天贡献至少6杯,这个工业区大概有2000个人上班,并且有越来越多的人加入每天一杯的行列。怎么可能每天200单。”
错误举例:“报告里走访的900家店的清单里有一行:来福士广场店,统计当天是周一。这报告可真聪明,在一个mall里挑了周一,周一你们去逛mall走商场么?动脑子吧。如果这个统计每个店就挑一天,写字楼多挑周四周五,mall多选周一,那就偏差很大了。”
4. 诉诸权威、诉诸多数
某专家是这么说的,很多人都这么说。他们这么说一定有理由,隐含的意思是他们一定掌握了我所暂时不知道的证据,看过我所没看过的案例,才这么说。
错误举例:“同为被国内美股投资者熟知的做空机构——Citron Research香橼研究,也在推特表明同样收到了该报告,但他们在推特表示,他们仍然看多瑞幸。美国拥有成熟的资本市场,这么多投资人也不是傻子。”
最近的多益网络董事长《实名带可靠证据举报武汉病毒研究所》,没有一个称得上证据。看来是徐董事长对“证据”这个词有不同的理解。哎。
5. 攻击观点持有人的资质和人品
一个人有缺点、无经验、以前干坏事,所以他的观点是错的。
错误举例:多益网络董事长徐波对医学完全不懂,他的举报是无效的,所以武汉病毒研究所就是清白的。
要注意,不可信观点不等于他的对立面就是对的。
攻击观点持有人的资质恰恰是诉诸权威的反面。
观点应该与人解耦。判断一个命题的真假,有且只有一种途径:看论证,看证据。
(六)
总的来说,人类的感觉对于特例还是典型、总体和样本、概率和可能性、偶然和必然,其实是毫无处理能力的。
人类对栩栩如生的故事做出更大的反应,并认为这样的个案会以更大的概率发生,并且有一定的必然性。而面对统计数字的时候,会不自觉地认为,所有的个案都应该非常接近平均数。
人类对讲故事的人也会做出更大的反应。第一反应不是判断这个人讲的故事是否真实,而是判断这个人是否可信。人类更喜欢对人做判断,而不是对事件本身做判断。
对抗的方法只有一个:
Talk is cheap.
Show me the evidence, and prove it.
发表回复