逻辑和直觉,是两种相反的能力。有的人逻辑强,有的人直觉好,这两种能力,是怎么培养训练而来的呢?
逻辑强表现在几个方面。一是因果链条推演,可以将复杂系统拆解成部件,并且演算出执行步骤。二是擅长记忆知识点,博闻强识,而且新的知识接收起来很快,一旦接收也不易忘记。
而直觉强的人则相反。脑中有战略终局的画面,有一种宏观的敏锐。虽然从 as-is 的现状到终局的发展路径并不能推演得很清晰,但对于终局各大玩家的心理动机更能把握。
这种描述是把我作为逻辑的范本,把PP和教主作为直觉的范本。
举几个例子。
高中的历史政治考试,我总是背不完所有的知识点,只能记得三成,而PP考试时则记得一清二楚,某句知识点出现在书上哪个位置,左下角还是右上角,会形象地出现在PP的脑海里。然而我发现,我所记得的三成知识点,时隔将近二十年,很多都还能记得。而PP当时记得一清二楚的知识点,考完试后不久就大部分忘记了。工作之后考CPA和法考也类似,我即使考完后好几年都还能记得,而PP考试时记得很快很多,考完之后很快忘记,好像刷新的记忆去记新的东西了。
短期记忆PP很强,长期记忆似乎我又更好一些,好像内存和硬盘的差别一样。我发现我记忆知识点是把它放进我的体系中,要把它融合进我的体系才能记住,而一旦记住就不容易忘记,因为已经成为体系中的一部分,以后便可以随时从中调取出来。而PP就是把这个知识点直接记住,连带着它周围的环境也一并记住。调取的时候,是通过周围这些有关无关的环境信息同时浮现在她的眼前。我大二时《概率统计》这门课程的期末考试最后一道大题,给了(X,Y)的样本数据,要求手算出最小二乘法下 y=ax+b 中 a,b 参数的值。结果我考试时忘记了 a,b 的公式,硬生生花了20分钟从最基本的原理入手把这个公式给推导出来,再进行计算。而PP在面对困难的题目不会如此。她会按照她的“直觉”编出一条公式。神奇的是,她凭直觉瞎蒙的公式,准确率异常高,就好像她真的会一样。
我的答案是推演出来的,PP的答案是生成出来的。
数学证明题的差别就更大了。我会逐步论证,链式推理,每一步都要求严谨,遇到困难我会从头推,如果实在推不下去了,那只能停在卡点处。而 PP 则是跳跃式论证,已知条件是起点,要证明的结论是终点,起点和终点已经确定,中间的路径一开始是空白,只要像拼图一样一块一块拼起来,不必沿袭固定的路径,手里拿着各种拼图块试一试,拼的上就行。遇到困难,她会把那一块拼图暂时放一边,继续拼其他拼图,最后实在找不到这一块拼图,她也会把其他拼图能拼的拼进去。
花这么多笔墨是为了形象说明“逻辑”和“直觉”这两种不同的能力的准确画像。而且我想强调的是,这两种能力并不意味着学习成绩好坏,也不是硕理科靠逻辑,文科靠直觉。事实上,PP、教主和我的学习成绩都很好,毕竟也是考上复旦交大的,而且也都是理科。逻辑侧重分析能力,直觉侧重决策能力,而两种能力都能发展出很强的学习能力。
有的AI人工智能算法也能分成这两种能力。2020年以前的人工智能属于逻辑强的小模型,用事先定义好的体系和规则推演出答案。GPT之后的生成式AI,则是属于依赖直觉的大模型,他的答案是生成出来的,质量很高,偶尔也会胡说八道,像极了PP。
而围棋AI AlphaGo甚至集两种能力于一身。也是从它身上,我们提炼出这两种能力殊途同归的本质。
AlphaGo的底层模型由两种网络模型组成:策略网络(policy network)和估值网络(value network)。Policy network对大局面作判断,找出大方向,它并不追求决策的完备和穷举,只要策略是相对较好的。它的输入是当前棋局局面,它的输出是下一步可能的选点方向。Value network要对每一步可能的下法做精确的推演,给每一步棋计算它的价值。它把每一步的终局精确地推演出来,把终局的优劣作为该分支的价值。
Policy network就像直觉,在宏观决策上把握大局;value network把握逻辑,精确推理确定具体的执行方案。AlphaGo在每一步的决策上都把这两个network相结合,效果极佳。
神奇的地方来了,policy network和value network的底层模型竟然是同一个模型,都是CNN卷积神经网络。同一个模型怎么会产生出截然不同的两种能力呢,它们的模型结构是一样的,训练用的数据也是类似的,唯一的区别就在它们的训练和推理方向是相反的!
用图示表示如下:
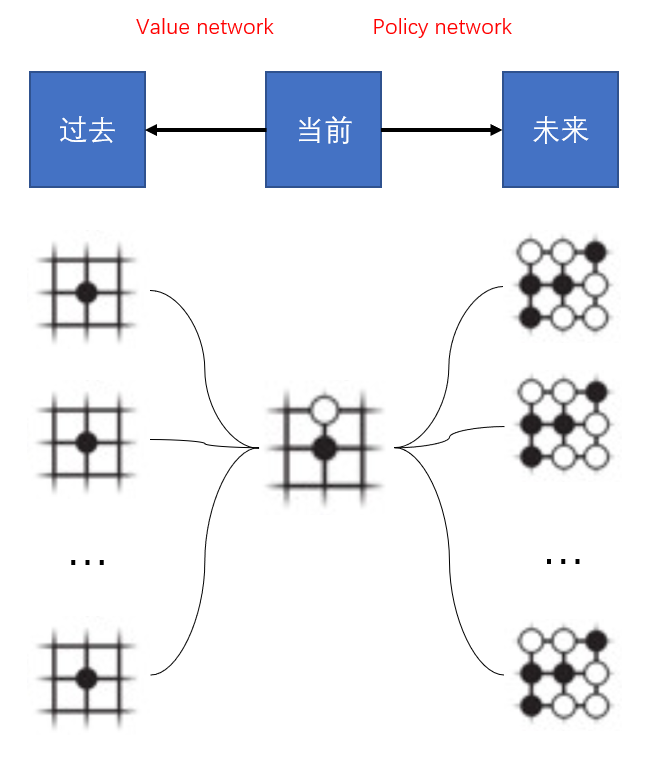
Policy network是依照上一步的局面,给下一步赋值。它只关心这个局面未来会怎么发展,不关心这个局面是怎么来的。从同一个当前局面演化而来的不同可能性结局,对policy network来说,共享同一个现状。
Value network是依照下一步的结果,给上一步赋值。它不关心未来会变成怎么样,它只关心这种局面是怎么来的。不同的路径如果都导向同一个棋局,对value network来说,这些路径都共享同一个结局。
抽象来说,policy network是过去推未来,value network是未来推过去。如果我们抛弃时间这个维度是单向流动的假设,而是既可以从未来到过去,也可以从过去到未来(至少在训练数据集的世界里是成立的),那么训练policy network和value network就是同一件事情:区别只有训练数据的遮罩方向。把未来遮起来,输入过去的状态,让模型进行前向推理,然后再跟实际的未来(只有抛弃时间单向流动的假设,才有可能存在“实际的未来”)进行比对,就是policy network的训练方式;把过去遮起来,输入未来的状态,让模型进行后向推理,然后再跟过去进行比对,就是value network的训练方式。

既然policy network就像想象力,value network就像逻辑性。也就是说,本质上人类的逻辑和直觉在大脑底层的先天结构上其实是一样的,并非有人先天就拥有逻辑或者直觉,这都是可以通过后天学习训练的!而且一种能力强的人,只要把他过往学习训练的方向调个个儿,便能习得相对的另一种能力。这一发现,将大大改进个体的学习方法、孩子的教育理论等。
这也解释了这两种能力为何并无文理偏向性的原因,即并非逻辑强的人只能擅长理科,直觉强的人只能擅长文科和艺术。其实就是在该领域中,学习训练时把输入和输出这么一反过来,就能分别训练出这两种能力了。
回想小时候读书学习的经历,也对上了。我小时候喜欢读的书为非虚构、科普类的书。看书时,我探求的是这一页的内容是什么机制导致的,或者书的作者在上一页是如何严密论证推理出当下内容的。当新的事物也能用我了解的机制所解释,或者我获得新的知识修补了我已有的机制。无论能不能被解释,我都扩张了我自己的体系和机制,这给我带来的阅读的乐趣。教主小时候喜欢读的是小说和漫画。阅读时,他并不享受回头看的乐趣,而是想象着下一页的故事将如何发展。他的阅读乐趣在于看实际发生的故事是否跟他想象的一致,无论是否一致都扩张了他的想象力。PP小时候喜欢读的也是小说,不过她不看漫画,而是看TVB港剧,发挥“黄编剧”的能力预测接下来的剧情发展。确实黄编剧现在的能力也是没得说,看着剧,甚至连下一句台词都常常能猜个七七八八,厉害。
回头看(后向推理)是学习分析归纳能力,要求精确严谨,一个反例的出现,便可以说明结论错了,推理错了。而向前看(前向推理)是学习演绎的能力,不求严谨,但追求多样化的可能性,反例的出现只能说明故事挑选了另外一种可能性发生,并不能说明你的想象和演绎错了。因为可能性并无对错之分。
发表回复